Harnessed: How Language and Music Mimicked Nature and Transformed Ape to Man (12 page)
Read Harnessed: How Language and Music Mimicked Nature and Transformed Ape to Man Online
Authors: Mark Changizi
Tags: #Non-Fiction
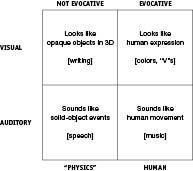
Figure 15
. Evocative stimuli (
right column
) are usually made with people, whereas nonevocative stimuli (
left column
) are more physics-related and sterile.
Do we find that evocativeness springs from the same human source within the auditory domain? Let’s start with speech. As we discussed in the previous chapter, speech sounds like solid-object physical events. “Solid-object physical events” amount to a sterile physics category of sound, akin in nerdiness to “three-dimensional world of opaque objects.” We are capable of mimicking lots of nonhuman sounds, and speech, then, amounts to yet another mimicry of this kind. Ironically, human speech does not sound
human
at all. It is consequently
not
evocative. (See the bottom left square of Figure 15 for speech’s place in the table.) Which brings us back to music, the other major kind of auditory stimulus people produce besides speech. Just as color is evocative but writing is not, music is evocative but speech sounds are not. This suggests that, just as color gets its emotionality from people, perhaps music gets
its
emotionality from people. Could it be that music, like Soylent Green, is made out of people? (Music has been placed at the bottom right of the table in Figure 15.)
If we believe that music sounds like people, then we greatly reduce the range of worldly sounds music may be mimicking. That amounts to progress: music is probably mostly not about birdsong, wind, water, math, and so on. But, unfortunately, humans make a wide variety of sounds, some in fundamentally different categories, such as speech, coughs, sneezes, laughter, heartbeats, chewing, walking, hammering, and so on. We’ll need a more specific theory than one that simply says music is made from people. Next, though, we ask why there isn’t any purely visual domain that is as exciting to us as music.
Going Solo
If the visual system and auditory system had competitive streaks, they might argue about which modality has the most compelling art. Each would be allowed to cite as examples only cases exclusively within its own modality: vision-only versus audition-only. This is a difficult contest to officiate. Should vision be allowed to cite all the features of visual design found in culture, such as clothes, cars, buildings, and everyday objects? If so, it would have a big leg up on audition, which is not nearly so involved in the design of our physical artifacts. Let’s agree not to include these, by virtue of an “official rule” that the art must be purchased by people for the purpose merely of enjoying the aesthetics, with no other functional benefit. That is, is it vision or audition that commands the greatest portion of the market for art and entertainment?
If you set it up in this way, audition trounces vision. Although the visual modality is found in huge markets like television, video games, and movies, these rely on audition as well. People put visual art on their walls, but that typically amounts to just a few purchases, whereas it is common to find people who own
thousands
of music albums. The market for the purely visual arts is miniscule compared to that for audition. This is counterintuitive, because if you ask most of us to name the most beautiful things we know of, we are likely to respond with a list of visuals. But when we vote with our pocketbooks, audition wins the solo artist contest. Why is that?
One possible explanation is simply that it is easier to carry on with the chores of life while music is in the background, whereas the visual arts inherently get in the way. Try driving or working or throwing a dinner party while admiring the Mona Lisa. But I suspect it is more than this. If it was merely because of the difficulty of enjoying visual arts while having a life, one might expect us to
want
to stare at beautiful visual art all day, if only we had nothing else pressing to do. Most of us, however, don’t exactly fancy the idea of watching visual images all day (without sound). Listening to music all day, however, sounds quite charming! And, in fact, many of us
do
spend our days listening to music.
The stark inequality of vision and audition in this competition for “best solo performer” in the arts is due to a fundamental ecological asymmetry. When we see things in the world, those things are typically making noise. Seeing without hearing therefore feels strange, unnatural, or as if it is missing something. But hearing without seeing is commonplace, because we hear all sorts of things we cannot see—when our eyes are closed, when the source is behind us, when the source is occluded, or when the environment is dark. Sights nearly always come with sounds, but sounds very commonly come without sights. And that’s why audition is happy to be a solo artist, but vision isn’t. Music is the single-modality artist extraordinaire.
While we now have some idea why there’s no solely visual art that rivals music, we still have barely begun our quest to understand why music is so compelling that we are
willing
to purchase thousands of albums.
At the Heart of a Theory of Music
If music sounds human in fundamental respects, as our discussion in the section before last suggested, then it seems to have made heroic efforts to obfuscate this fact. I readily admit that music doesn’t sound human to
me
—not
consciously
, at least. But recall the section titled “Below the Radar” from Chapter 1, where I said that we don’t necessarily expect cultural artifacts to mimic nature “all the way up.” It may be the case that much of our lower-level auditory apparatus thinks that music sounds like humans, but that because of certain high-level dissimilarities,
we
—our conscious selves—don’t notice it. How, then, can I hope to convince anyone? I have to convince
you
, after all, not your lower-level auditory areas!
What we need are some qualifying hurdles that a theory of music should have to leap over to gain a hearing . . . hurdles that, once cleared, will serve to persuade some of Earth’s teeming music buffs that music does indeed sound like people moving. Toward this end, here are four such hurdles—questions that any aspiring theory of music might hope to answer.
Brain
: Why do we have a brain for music?
Emotion
: Why is music emotionally evocative?
Dance
: Why do we dance?
Structure
: Why is music organized the way it is?
If a theory can answer all four questions, then I believe we should start paying attention.
To help clarify what I mean by these questions, let’s run through them in the context of a particular lay theory of music: the “heartbeat” theory. Although there is probably more than just one heartbeat theory held by laypeople, the main theme appears to be that a heart has a beat, as music does. Of course, we don’t typically hear our own heartbeat, much less others’, so when the theory is fleshed out, it is often suggested that the fundamental beat was laid down when we were in utero. One of the constants of the good fetal life was Momma’s heartbeat, and music takes us back to those oceanic, one-with-the-universe feelings we long ago lost. I’m not suggesting that this is a good theory, by any means, but it will aid me in illustrating the four hurdles. I would be hesitant, by the way, to call this “lub-dub” theory of music crazy—our understanding of the origins of music is so woeful that any nonspooky theory is worth a look. Let’s see how lub-dubs fare with our four hurdles for a theory of music.
The first hurdle was this: “Why do we have a brain for music?” That is, why are our brains capable of processing music? For example, fax machines are designed to process the auditory modulations occurring in fax machine communication, but to
our
ears fax machines sound like a fairly continuous
screech-brrr
—we don’t have brains capable of processing fax machine sounds. Music may well sound homogeneously
screechy-brrrey
to nonhuman ears, but it sounds richly dynamic and structured to
our
ears. How might the lub-dub theorist explain why we have a brain for music? Best I can figure, the lub-dubber could say that our in-utero days of warmth and comfort get strongly associated to Momma’s heartbeat, and the musical beat taps into those associations, bringing back warm fetus feelings. One difficulty for this hypothesis is that learned associations often don’t last forever, so why would those Momma’s-heartbeat associations be so strong among adults? There are lots of beatlike stimuli outside of the womb: some are nice, some are not nice. Why wouldn’t those out-of-the-womb sounds become the dominant associations, with Momma’s heartbeat washed away? And if Momma’s lub-dubs are, for some reason, not washed away, then why aren’t there other in utero experiences that forever stay with us? Why don’t we, say, like to wear artificial umbilical cords, thereby evoking recollections of the womb? And why, at any rate, do we think we were so happy in the womb? Maybe those days, supposing they leave any trace at all, are associated with nothing whatsoever. (Or perhaps with horror.) The lub-dub theory of music does not have a plausible story for why we have a brain ready and eager to soak up a beat.
The lub-dub theory of music origins also comes up short in the second major demand on a theory of music: that it explain why music is evocative, or emotional. This was the subject of the previous section. Heartbeats
are
made by people, but heartbeat sounds amount to a one-dimensional parameter—faster or slower rate—and are not sufficiently rich to capture much of the range of human emotion. Accordingly, heartbeats won’t help much in explaining the range of emotions music can
elicit
in listeners. Psychophysiologists who look for physiological correlates of emotion take a
variety
of measurements (e.g., heart rate, blood pressure, skin conductance), not just one. Heart sounds aren’t rich enough to tug at all music’s heartstrings.
Heartbeats also fail the “dance” hurdle. The “dance” requirement is that we explain why it is that music should elicit dance. This fundamental fact about music is a
strange
thing for sounds to do. In fact, it is a strange thing for
any
stimulus to do, in
any
modality. For lub-dubs, the difficulty for the dance hurdle is that even if lub-dubs were fondly recalled by us, and even if they managed to elicit a wide range of emotions, we would have no idea why they should provoke post-uterine people to move, given that even fetuses don’t move to Momma’s heartbeat.
The final requirement of a theory of music is that it must explain the structure of music, a tall order. Lub-dubs
do
have a beat, of course, but heartbeats are far too simple to begin to explain the many other structural regularities found in music. For starters, where is the melody?
Sorry, Mom (again). Thanks for the good times in your uterus, but I’m afraid your heartbeats are not the source of my fascination with music.
Although the lub-dub theory fails the four requirements for a theory of music, the music-sounds-like-human-movement theory of music, as we will see, has answers to all four. We have a brain for music because possessing auditory mechanisms for recognizing what people are doing around us is clearly advantageous. Music is evocative because it sounds like human behaviors, many of which are expressive in their nature—something we will discuss further in a few pages. Music gets us dancing because, as we will also discuss, we social apes are prone to mimic the movements of others. And, finally, the movement theory is sufficiently powerful that it can explain a lot of the structure of music—
that
will require the upcoming chapter and the Encore (at the end of the book) to describe.
Underlying Overtones
The heartbeat theory suffered cardiac arrest, but it was never intended as a serious contender. It was just a prop for illustrating the four hurdles. Speech, on the other hand, is a much more plausible starting point as a foundation for music. But haven’t we
already
discussed speech? Wasn’t that what the previous chapter was about? We concluded then that speech sounds like solid-object physical events: the structural regularities found among solid-object events are reflected in the phonological patterns of human speech. Speech is all about the phonemes, and how closely they mimic nature’s pattern of hits, slides, and ring sounds. Music, on the other hand, cares not a whit for phonemes. Although music can often have words to be sung, music usually gets its identity not from the words, but from the rhythm and tune. Two songs with different words, but with the same rhythm and pitch sequence, are deemed by us to be the same tune, just with different words. That’s why we use the phrase “put words to the music”—because the words (and the phonemes) are not properly part of the meat of the music. The most central auditory feature of speech—its phonological characteristics—is mostly irrelevant to music, making speech an unlikely place to look for the origins of music.
Music is not only missing the phonological core of speech, but it is also missing another fundamental aspect of speech, its most evocative aspect: the meaning, or semantics. If music has its source in speech, and is evocative because of the evocative nature of speech, then why wouldn’t music
require
words with meaning, whether metaphorical or direct? Yet, as mentioned above, neither phonology nor words is an essential ingredient of music. (Although phonology and words are key ingredients in poetry.)