The Information (75 page)
The collision of names, the exhaustion of names—it has happened before, if never on this scale. Ancient naturalists knew perhaps five hundred different plants and, of course, gave each a name. Through the fifteenth century, that is as many as anyone knew. Then, in Europe, as printed books began to spread with lists and drawings, an organized, collective knowledge came into being, and with it, as the historian Brian Ogilvie has shown, the discipline called natural history.
♦
The first botanists discovered a profusion of names. Caspar Ratzenberger, a student at Wittenberg in the 1550s, assembled a herbarium and tried to keep track: for one species he noted eleven names in Latin and German:
Scandix, Pecten veneris, Herba scanaria, Cerefolium aculeatum, Nadelkrautt, Hechelkam, NadelKoerffel, Venusstrahl, Nadel Moehren, Schnabel Moehren,
Schnabelkoerffel
.
♦
In England it would have been called
shepherd’s needle
or
shepherd’s comb
. Soon enough the profusion of species overtook the profusion of names. Naturalists formed a community; they corresponded, and they traveled. By the end of the century a Swiss botanist had published a catalogue of 6,000 plants.
♦
Every naturalist who discovered a new one had the privilege and the responsibility of naming it; a proliferation of adjectives and compounds was inevitable, as were duplication and redundancy. To
shepherd’s needle
and
shepherd’s comb
were added, in English alone,
shepherd’s bag, shepherd’s purse, shepherd’s beard, shepherd’s bedstraw, shepherd’s bodkin, shepherd’s cress, shepherd’s hour-glass, shepherd’s rod, shepherd’s gourd, shepherd’s joy, shepherd’s knot, shepherd’s myrtle, shepherd’s peddler, shepherd’s pouche, shepherd’s staff, shepherd’s teasel, shepherd’s scrip
, and
shepherd’s delight
.
Carl Linnaeus had yet to invent taxonomy; when he did, in the eighteenth century, he had 7,700 species of plants to name, along with 4,400 animals. Now there are about 300,000, not counting insects, which add millions more. Scientists still try to name them all: there are beetle species named after Barack Obama, Darth Vader, and Roy Orbison. Frank Zappa has lent his name to a spider, a fish, and a jellyfish.
“The name of a man is like his shadow,”
♦
said the Viennese onomatologist Ernst Pulgram in 1954. “It is not of his substance and not of his soul, but it lives with him and by him. Its presence is not vital, nor its absence fatal.” Those were simpler times.
When Claude Shannon took a sheet of paper and penciled his outline of the measures of information in 1949, the scale went from tens of bits to hundreds to thousands, millions, billions, and trillions. The transistor was one year old and Moore’s law yet to be conceived. The top of the pyramid was Shannon’s estimate for the Library of Congress—one hundred trillion bits, 10
14
. He was about right, but the pyramid was growing.
After bits came kilobits, naturally enough. After all, engineers had
coined the word
kilobuck
—“a scientist’s idea of a short way to say ‘a thousand dollars,’”
♦
The New York Times
helpfully explained in 1951. The measures of information climbed up an exponential scale, as the realization dawned in the 1960s that everything to do with information would now grow exponentially. That idea was casually expressed by Gordon Moore, who had been an undergraduate studying chemistry when Shannon jotted his note and found his way to electronic engineering and the development of integrated circuits. In 1965, three years before he founded the Intel Corporation, Moore was merely, modestly suggesting that within a decade, by 1975, as many as 65,000 transistors could be combined on a single wafer of silicon. He predicted a doubling every year or two—a doubling of the number of components that could be packed on a chip, but then also, as it turned out, the doubling of all kinds of memory capacity and processing speed, a halving of size and cost, seemingly without end.
Kilobits could be used to express speed of transmission as well as quantity of storage. As of 1972, businesses could lease high-speed lines carrying data as fast as 240 kilobits per second. Following the lead of IBM, whose hardware typically processed information in chunks of eight bits, engineers soon adopted the modern and slightly whimsical unit, the byte. Bits and bytes. A kilobyte, then, represented 8,000 bits; a megabyte (following hard upon), 8 million. In the order of things as worked out by international standards committees,
mega
- led to
giga-, tera-, peta-
, and
exa-
, drawn from Greek, though with less and less linguistic fidelity. That was enough, for everything measured, until 1991, when the need was seen for the zettabyte (1,000,000,000,000,000,000,000) and the inadvertently comic sounding yottabyte (1,000,000,000,000, 000,000,000,000). In this climb up the exponential ladder information left other gauges behind. Money, for example, is scarce by comparison. After kilobucks, there were megabucks and gigabucks, and people can joke about inflation leading to terabucks, but all the money in the world, all the wealth amassed by all the generations of humanity, does not amount to a petabuck.
The 1970s were the decade of megabytes. In the summer of 1970, IBM introduced two new computer models with more memory than ever before: the Model 155, with 768,000 bytes of memory, and the larger Model 165, with a full megabyte, in a large cabinet. One of these room-filling mainframes could be purchased for $4,674,160. By 1982 Prime Computer was marketing a megabyte of memory on a single circuit board, for $36,000. When the publishers of the
Oxford English Dictionary
began digitizing its contents in 1987 (120 typists; an IBM mainframe), they estimated its size at a gigabyte. A gigabyte also encompasses the entire human genome. A thousand of those would fill a terabyte. A terabyte was the amount of disk storage Larry Page and Sergey Brin managed to patch together with the help of $15,000 spread across their personal credit cards in 1998, when they were Stanford graduate students building a search-engine prototype, which they first called BackRub and then renamed Google. A terabyte is how much data a typical analog television station broadcasts daily, and it was the size of the United States government’s database of patent and trademark records when it went online in 1998. By 2010, one could buy a terabyte disc drive for a hundred dollars and hold it in the palm of one hand. The books in the Library of Congress represent about 10 terabytes (as Shannon guessed), and the number is many times more when images and recording music are counted. The library now archives web sites; by February 2010 it had collected 160 terabytes’ worth.
As the train hurtled onward, its passengers sometimes felt the pace foreshortening their sense of their own history. Moore’s law had looked simple on paper, but its consequences left people struggling to find metaphors with which to understand their experience. The computer scientist Jaron Lanier describes the feeling this way: “It’s as if you kneel to plant the seed of a tree and it grows so fast that it swallows your whole town before you can even rise to your feet.”
♦
A more familiar metaphor is the cloud. All that information—all that information capacity—looms over us, not quite visible, not quite tangible, but awfully real; amorphous, spectral; hovering nearby, yet not
situated in any one place. Heaven must once have felt this way to the faithful. People talk about shifting their lives to the cloud—their informational lives, at least. You may store photographs in the cloud; Google will manage your business in the cloud; Google is putting all the world’s books into the cloud; e-mail passes to and from the cloud and never really leaves the cloud. All traditional ideas of privacy, based on doors and locks, physical remoteness and invisibility, are upended in the cloud.
Money lives in the cloud; the old forms are vestigial tokens of knowledge about who owns what, who owes what. To the twenty-first century these will be seen as anachronisms, quaint or even absurd: bullion carried from shore to shore in fragile ships, subject to the tariffs of pirates and the god Poseidon; metal coins tossed from moving cars into baskets at highway tollgates and thereafter trucked about (now the history of your automobile is in the cloud); paper checks torn from pads and signed in ink; tickets for trains, performances, air travel, or anything at all, printed on weighty perforated paper with watermarks, holograms, or fluorescent fibers; and, soon enough, all forms of cash. The economy of the world is transacted in the cloud.
Its physical aspect could not be less cloudlike. Server farms proliferate in unmarked brick buildings and steel complexes, with smoked windows or no windows, miles of hollow floors, diesel generators, cooling towers, seven-foot intake fans, and aluminum chimney stacks.
♦
This hidden infrastructure grows in a symbiotic relationship with the electrical infrastructure it increasingly resembles. There are information switchers, control centers, and substations. They are clustered and distributed. These are the wheel-works; the cloud is their avatar.
The information produced and consumed by humankind used to vanish—that was the norm, the default. The sights, the sounds, the songs, the spoken word just melted away. Marks on stone, parchment, and paper were the special case. It did not occur to Sophocles’ audiences that it would be sad for his plays to be lost; they enjoyed the show. Now expectations have inverted. Everything may be recorded and preserved,
at least potentially: every musical performance; every crime in a shop, elevator, or city street; every volcano or tsunami on the remotest shore; every card played or piece moved in an online game; every rugby scrum and cricket match. Having a camera at hand is normal, not exceptional; something like 500 billion images were captured in 2010. YouTube was streaming more than a billion videos a day. Most of this is haphazard and unorganized, but there are extreme cases. The computer pioneer Gordon Bell, at Microsoft Research in his seventies, began recording every moment of his day, every conversation, message, document, a megabyte per hour or a gigabyte per month, wearing around his neck what he called a “SenseCam” to create what he called a “LifeLog.” Where does it end? Not with the Library of Congress.
It is finally natural—even inevitable—to ask how much information is in the universe. It is the consequence of Charles Babbage and Edgar Allan Poe saying, “No thought can perish.” Seth Lloyd does the math. He is a moon-faced, bespectacled quantum engineer at MIT, a theorist and designer of quantum computers. The universe, by existing, registers information, he says. By evolving in time, it processes information. How much? To figure that out, Lloyd takes into account how fast this “computer” works and how long it has been working. Considering the fundamental limit on speed,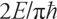 operations per second (“where
operations per second (“where
E
is the system’s average energy above the ground state and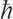 = 1.0545 × 10
= 1.0545 × 10
−34
joule-sec is Planck’s reduced constant”), and on memory space, limited by entropy to
S
/
k
B
ln 2 (“where
S
is the system’s thermodynamic entropy and
k
B
= 1.38 × 10
−23
joules/K is Boltzmann’s constant”), along with the speed of light and the age of the universe since the Big Bang, Lloyd calculates that the universe can have performed something on the order of 10
120
“ops” in its entire history.
♦
Considering “every degree of freedom of every particle in the universe,” it could now hold something like 10
90
bits. And counting.
(And Such Like)
Sorry for all the ups and downs of the web site in recent days. The way I understand it, freakish accumulations of ice weigh down the branches of the Internet and trucks carrying packets of information skid all over the place.