Attract Visitors to Your Site: The Mini Missing Manual (5 page)
Read Attract Visitors to Your Site: The Mini Missing Manual Online
Authors: Matthew MacDonald
By this point, you might be getting a little nervous. Given the fact that Google handles hundreds of millions of searches a day, isn’t it possible for a measly one-cent bid to quickly put you and your site into bankruptcy? Fortunately, Google’s got the solution for this, too. You just tell Google how much you’re willing to pay per day. Once you hit your limit, Google stops showing your ad.
Interestingly, the bid amount isn’t the only factor that determines how often your ad appears. Popularity is also important. If Google shows your ad over and over again and it never gets a click, Google realizes that your ad just isn’t working, and lets you know that with an automatic email message. It may then start showing your ad significantly less often, or stop showing it altogether, until you improve it.
AdWords can be competitive. To have a chance against all the AdWords sharks, you need to know how much a click is worth to your site. For example, if you sell monogrammed socks, you need to know what percentage of visitors actually
buy
something (called the
conversion rate
) and how much they’re likely to spend. A typical cost-per-click hovers around 75 cents, but there’s a wide range. At last measure, the word
free
topped the cost-per-click charts at $2.26, while the keyword combination
llama care
could be had for a song—a mere 5 cents. (And in recent history, law firms have bid “mesothelioma”—an asbestos-related cancer that could become the basis of a class-action lawsuit—up close to $100.) Before you sign up with AdWords, it’s a good idea to conduct some serious research to find out the recent prices of the keywords you want
to use.
Note: You can learn more about AdWords from
Google: The Missing Manual
, which includes a whole chapter on it, or on Google’s AdWords site (
http://adwords.google.com/
). For a change of pace, go to
http://www.iterature.com/adwords/
for a story about an artist’s attempt to use AdWords to distribute poetry, and why it failed.
Hiding from search engines
In rare situations, you might create a page that you
don’t
want to turn up in a search result. The most common reason is because you’ve posted some information that you want to share with only a few friends, like the latest Amazon e-coupons. If Google indexes your site, thousands of visitors could come your way, sucking up your bandwidth for the rest of the month. Another reason may be that you’re posting something semi-private that you don’t want other people to stumble across, like a story about how you stole a dozen staplers from your boss. If you fall into the latter category, be very cautious. Keeping search engines away is the least of your problems—once a site’s on the Web, it
will
be discovered. And once it’s discovered, it won’t ever go away (see the box
“Web Permanence”
).
But you can do at least one thing to minimize your site’s visibility or, possibly, keep it off search engines altogether. To understand how this procedure works, recall that search engines do their work in several stages. In the first stage, a robot program crawls across the Web, downloading sites. You can tell this robot to not index your site, or to ignore a portion of it, in several ways (not all search engines respect these rules, but most—including Google—do).
To keep a robot away from a single page, add the
robots
meta element to the page. Use the content value
noindex
, as shown here:
Remember, like all meta elements, you place this one in the section of your web page.
Alternatively, you can use
nofollow
to tell robots to index the current page, but not to follow any of its links:
If you want to block larger portions of your site, you’re better off creating a specialized file called
robots.txt
, and placing it in the top-level folder of your site. The robot automatically checks this file first, before it goes any further. The content inside the
robots.txt
file sets the rules.
If you want to stop a robot from indexing any part of your site, add this to the
robots.txt
file:
User-Agent: *
Disallow: /
The User-Agent part identifies the type of robot you’re addressing, and an asterisk represents all robots. The Disallow part indicates what part of the website is off limits; a single forward slash represent the whole site.
To rope off just the Photos subfolder on your site, use this (making sure to match the capitalization of the folder name exactly):
User-Agent: *
Disallow: /Photos
To stop a robot from indexing certain types of content (like images), use this:
User-Agent: *
Disallow: /*.gif
Disallow: /*.jpeg
As this example shows, you can put as many Disallow rules as you want in the
robots.txt
file, one after the other.
Remember, the
robots.txt
file is just a set of
guidelines
for search engine robots, it’s not a form of access control. In other words, it’s similar to posting a “No Flyers” sign on your mailbox—it works only as long as advertisers choose to heed it.
Tip: You can learn much more about robots, including how to tell when they visit your site and how to restrict the robots coming from specific search engines, at
http://www.robotstxt.org/
.
Tracking Visitors
As a website owner, you’ll try a lot of different tactics to promote your site. Naturally, some will work while others won’t—and you need to keep the good strategies and prune those that fail. To do this successfully, you need a way to assess how your website is performing.
Almost every web hosting company (except free web hosts) gives you some way to track the number of visitors to your site (see
Figure 1-9
). Ask your hosting company how to use these tools. Usually, you need to log on to a “control panel” or “my account” section of your web host’s site. You’ll see a variety of options there—look for an icon labeled “site counters” or “web traffic.”
With more high-end hosting services, you often have more options for viewing your site’s traffic statistics. Some hosts provide the raw
web server logs
, which store detailed, blow-by-blow information about every one of your visitors. This information includes the time a visitor came, their IP addresses (an
IP address
is a numeric code that uniquely identifies a computer on the Internet), their browser type, what site referred them to you, whether they ran into an error, what pages they ignored, what pages they loved, and so on. To make sense of this information, you need to feed it into a high-powered program that performs
log analysis
. These programs are often complex and expensive. An equally powerful but much more convenient approach is to use the Google Analytics tracking service, described next.
UP TO SPEED
Web Permanence
You’ve probably heard a lot of talk about the ever-changing nature of the Web. Maybe you’re worried that the links you create today will lead to dead sites or missing pages tomorrow. Well, there’s actually a much different issue taking shape—copies of old sites that just won’t go away.
Once you put your work on the Web, you’ve lost control of it forever. The corollary to this sobering thought is: Always make sure you aren’t posting something that’s illegal, infringes on copyright, is personally embarrassing, or could get you fired. Because once you put this material out on the Web, it may never go away.
For example, imagine you accidentally reveal your company’s trade secret for carrot-flavored chewing gum. A few weeks later, an excited customer links to your site. You realize your mistake, and pull the pages off your Web server. But have you really contained the problem?
Assuming the Google robot has visited your site recently (which is more than likely), Google now has a copy of your old website. Even worse, people can get this
cached
(saved) copy from Google if they know about the
cache
keyword. For example, if the offending page’s URL is
http://www.GumLover.com/newProduct.htm/
, a savvy Googler can get the old copy of your page using the search “
cache:http://www.GumLover.com/newProduct.htm/
.” (Less savvy visitors might still stumble onto a cached page by clicking the Cached link that appears after each search result in Google’s listings.) Believe it or not, this trick’s been used before to get accidentally leaked information, ranging from gossip to software license keys.
You can try to get your page out of Google’s cache as quickly as possible using the Remove URL feature at
http://www.google.com/webmasters/tools/removals/
. But even if this works, you’re probably starting to see the problem—there’s no way to know how many search engines have made copies of your work. Interested people who notice that you pulled down information will hit these search engines and copy the details to their own sites, making it pretty near impossible to eliminate the lingering traces of your mistake. There are even catalogs dedicated to preserving old websites for posterity (see the Wayback Machine at
http://www.archive.org/
).
Understanding Google Analytics
In 2005, Google purchased Urchin, one of the premium web tracking companies. They transformed it into
Google Analytics
and abolished its hefty $500/month price tag, making it free for everyone. Today, Google Analytics just might be the best way to see what’s happening on any website, whether you’re building a three-page site about dancing hamsters or a massive compendium of movie reviews.
Google Analytics is refreshingly simple. Unlike other log analysis tools, it doesn’t ask you to provide server logs or other low-level information. Instead, it tracks all the information you need
on its own
. It stores this information indefinitely, and lets you analyze it any time with a range of snazzy web reports.
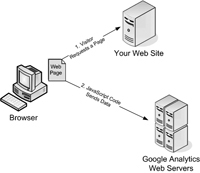
To use Google Analytics, you need to add a small snippet of Java-Script code to every web page you want to track (usually, that’s every page on your site). Once you get the JavaScript code in place, everything works seamlessly. When a visitor heads to a page on your site, the browser sends a record of the request to Google’s army of monster web servers, which store it for later analysis. The visitor doesn’t see the Google Analytics stuff.
Figure 1-10
shows you how it works.
Note: JavaScript is a type of mini-program that runs inside a browser. Virtually every Web browser in existence supports it.