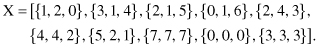Data Mining (13 page)
Authors: Mehmed Kantardzic
There is a possibility for reducing complexity of the algorithm by partitioning the data into n-dimensonal cells. If any cell and its directly adjacent neighbors contain more than k points, then the points in the cell are deemed to lie in a dense area of the distribution so the points contained are unlikely to be outliers. If the number of points is less than k, then all points in the cell are potential outliers. Hence, only a small number of cells need to be processed and only a relatively small number of distances need to be calculated for outlier detection.
Model-based techniques
are the third class of outlier-detection methods. These techniques simulate the way in which humans can distinguish unusual samples from a set of other similar samples. These methods define the basic characteristics of the sample set, and all samples that deviate from these characteristics are outliers. The sequential-exception technique is one possible approach that is based on a dissimilarity function. For a given set of n samples, a possible dissimilarity function is the total variance of the sample set. Now, the task is to define the smallest subset of samples whose removal results in the greatest reduction of the dissimilarity function for the residual set. The general task of finding outliers using this method can be very complex (combinational explosion of different selections of the set of potential outliers—the so called exception set), and it can be theoretically defined as an NP-hard problem (i.e., intractable). If we settle for a less-than-optimal answer, the algorithm’s complexity can be reduced to the linear level, using a sequential approach. Using the greedy method, the algorithm reduces the size sequentially, sample by sample (or subset by subset), by selecting at each step the one that causes the greatest decrease in the total variance.
Many data-mining algorithms are robust and as such tolerant to outliers but were specifically optimized for clustering or classification in large data sets. It includes clustering algorithms such as Balanced and Iterative Reducing and Clustering Using Hierarchies (BIRCH) and Density-Based Spatial Clustering of Applications with Noise (DBSCAN), k nearest neighbor (kNN) classification algorithms, and different neural networks. These methodologies are explained with more details later in the book, but the reader has to be aware about applicability of these techniques as powerful tools for outliers’ detection. For example, in the data set represented in Figure
2.9
, clustering-based methods consider a cluster of small sizes, including the size of one sample, as clustered outliers. Note that since their main objective is clustering, these methods are not always optimized for outlier detection. In most cases, the outlier detection criteria are implicit and cannot easily be inferred from the clustering procedures.
Figure 2.9.
Determining outliers through clustering.

Most of outlier detection techniques have only focused on continuous real-valued data attributes, and there has been little focus on categorical data. Most approaches require cardinal or at the least ordinal data to allow vector distances to be calculated, and have no mechanism for processing categorical data with no implicit ordering.
2.7 REVIEW QUESTIONS AND PROBLEMS
1. Generate the tree structure of data types explained in Section 2.1.
2. If one attribute in the data set is student grade with values A, B, C, D, and F, what type are these attribute values? Give a recommendation for preprocessing of the given attribute.
3. Explain why “the curse of dimensionality” principles are especially important in understanding large data sets.
4. Every attribute in a 6-D sample is described with one out of three numeric values {0, 0.5, 1}. If there exist samples for all possible combinations of attribute values, what will be the number of samples in a data set and what will be the expected distance between points in a 6-D space?
5. Derive the formula for min–max normalization of data on [−1, 1] interval.
6. Given 1-D data set X = {−5.0, 23.0, 17.6, 7.23, 1.11}, normalize the data set using
(a)
decimal scaling on interval [−1, 1],
(b)
min–max normalization on interval [0, 1],
(c)
min–max normalization on interval [−1, 1], and
(d)
standard deviation normalization.
Compare the results of previous normalizations and discuss the advantages and disadvantages of the different techniques.
7. Perform data smoothing using a simple rounding technique for a data set

and present the new data set when the rounding is performed to the precision of
(a)
0.1 and
(b)
1.
8. Given a set of 4-D samples with missing values,
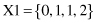
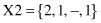

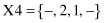
if the domains for all attributes are [0, 1, 2], what will be the number of “artificial” samples if missing values are interpreted as “don’t care values” and they are replaced with all possible values for a given domain?
9. A 24-h, time-dependent data set X is collected as a training data set to predict values 3 h in advance. If the data set X is

(a)
What will be a standard tabular representation of data set X if
(i)
the window width is 6, and a prediction variable is based on the difference between the current value and the value after 3 h. What is the number of samples?
(ii)
the window 4width is 12, and the prediction variable is based on ratio. What is the number of samples?
(b)
Plot discrete X values together with computed 6- and 12-h MA.
(c)
Plot time-dependent variable X and its 4-h EMA.
10. The number of children for different patients in a database is given with a vector
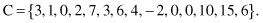
Find the outliers in set C using standard statistical parameters mean and variance.
If the threshold value is changed from ±3 standard deviations to ±2 standard deviations, what additional outliers are found?
11. For a given data set X of 3-D samples,