Data Mining (2 page)
Authors: Mehmed Kantardzic
PREFACE TO THE FIRST EDITION
The modern technologies of computers, networks, and sensors have made data collection and organization an almost effortless task. However, the captured data need to be converted into information and knowledge from recorded data to become useful. Traditionally, the task of extracting useful information from recorded data has been performed by analysts; however, the increasing volume of data in modern businesses and sciences calls for computer-based methods for this task. As data sets have grown in size and complexity, so there has been an inevitable shift away from direct hands-on data analysis toward indirect, automatic data analysis in which the analyst works via more complex and sophisticated tools. The entire process of applying computer-based methodology, including new techniques for knowledge discovery from data, is often called data mining.
The importance of data mining arises from the fact that the modern world is a data-driven world. We are surrounded by data, numerical and otherwise, which must be analyzed and processed to convert it into information that informs, instructs, answers, or otherwise aids understanding and decision making. In the age of the Internet, intranets, data warehouses, and data marts, the fundamental paradigms of classical data analysis are ripe for changes. Very large collections of data—millions or even hundred of millions of individual records—are now being stored into centralized data warehouses, allowing analysts to make use of powerful data mining methods to examine data more comprehensively. The quantity of such data is huge and growing, the number of sources is effectively unlimited, and the range of areas covered is vast: industrial, commercial, financial, and scientific activities are all generating such data.
The new discipline of data mining has developed especially to extract valuable information from such huge data sets. In recent years there has been an explosive growth of methods for discovering new knowledge from raw data. This is not surprising given the proliferation of low-cost computers (for implementing such methods in software), low-cost sensors, communications, and database technology (for collecting and storing data), and highly computer-literate application experts who can pose “interesting” and “useful” application problems.
Data-mining technology is currently a hot favorite in the hands of decision makers as it can provide valuable hidden business and scientific “intelligence” from large amount of historical data. It should be remembered, however, that fundamentally, data mining is not a new technology. The concept of extracting information and knowledge discovery from recorded data is a well-established concept in scientific and medical studies. What is new is the convergence of several disciplines and corresponding technologies that have created a unique opportunity for data mining in scientific and corporate world.
The origin of this book was a wish to have a single introductory source to which we could direct students, rather than having to direct them to multiple sources. However, it soon became apparent that a wide interest existed, and potential readers other than our students would appreciate a compilation of some of the most important methods, tools, and algorithms in data mining. Such readers include people from a wide variety of backgrounds and positions, who find themselves confronted by the need to make sense of large amount of raw data. This book can be used by a wide range of readers, from students wishing to learn about basic processes and techniques in data mining to analysts and programmers who will be engaged directly in interdisciplinary teams for selected data mining applications. This book reviews state-of-the-art techniques for analyzing enormous quantities of raw data in a high-dimensional data spaces to extract new information useful in decision-making processes. Most of the definitions, classifications, and explanations of the techniques covered in this book are not new, and they are presented in references at the end of the book. One of the author’s main goals was to concentrate on a systematic and balanced approach to all phases of a data mining process, and present them with sufficient illustrative examples. We expect that carefully prepared examples should give the reader additional arguments and guidelines in the selection and structuring of techniques and tools for his or her own data mining applications. A better understanding of the implementational details for most of the introduced techniques will help challenge the reader to build his or her own tools or to improve applied methods and techniques.
Teaching in data mining has to have emphasis on the concepts and properties of the applied methods, rather than on the mechanical details of how to apply different data mining tools. Despite all of their attractive “bells and whistles,” computer-based tools alone will never provide the entire solution. There will always be the need for the practitioner to make important decisions regarding how the whole process will be designed, and how and which tools will be employed. Obtaining a deeper understanding of the methods and models, how they behave, and why they behave the way they do is a prerequisite for efficient and successful application of data mining technology. The premise of this book is that there are just a handful of important principles and issues in the field of data mining. Any researcher or practitioner in this field needs to be aware of these issues in order to successfully apply a particular methodology, to understand a method’s limitations, or to develop new techniques. This book is an attempt to present and discuss such issues and principles and then describe representative and popular methods originating from statistics, machine learning, computer graphics, data bases, information retrieval, neural networks, fuzzy logic, and evolutionary computation.
In this book, we describe how best to prepare environments for performing data mining and discuss approaches that have proven to be critical in revealing important patterns, trends, and models in large data sets. It is our expectation that once a reader has completed this text, he or she will be able to initiate and perform basic activities in all phases of a data mining process successfully and effectively. Although it is easy to focus on the technologies, as you read through the book keep in mind that technology alone does not provide the entire solution. One of our goals in writing this book was to minimize the hype associated with data mining. Rather than making false promises that overstep the bounds of what can reasonably be expected from data mining, we have tried to take a more objective approach. We describe with enough information the processes and algorithms that are necessary to produce reliable and useful results in data mining applications. We do not advocate the use of any particular product or technique over another; the designer of data mining process has to have enough background for selection of appropriate methodologies and software tools.
MEHMED KANTARDZIC
Louisville
August 2002
1
DATA-MINING CONCEPTS
Chapter Objectives
- Understand the need for analyses of large, complex, information-rich data sets.
- Identify the goals and primary tasks of data-mining process.
- Describe the roots of data-mining technology.
- Recognize the iterative character of a data-mining process and specify its basic steps.
- Explain the influence of data quality on a data-mining process.
- Establish the relation between data warehousing and data mining.
1.1 INTRODUCTION
Modern science and engineering are based on using
first-principle models
to describe physical, biological, and social systems. Such an approach starts with a basic scientific model, such as Newton’s laws of motion or Maxwell’s equations in electromagnetism, and then builds upon them various applications in mechanical engineering or electrical engineering. In this approach, experimental data are used to verify the underlying first-principle models and to estimate some of the parameters that are difficult or sometimes impossible to measure directly. However, in many domains the underlying first principles are unknown, or the systems under study are too complex to be mathematically formalized. With the growing use of computers, there is a great amount of data being generated by such systems. In the absence of first-principle models, such readily available data can be used to derive models by estimating useful relationships between a system’s variables (i.e., unknown input–output dependencies).
Thus there is currently a paradigm shift from classical modeling and analyses based on first principles to developing models and the corresponding analyses directly from data.
We have gradually grown accustomed to the fact that there are tremendous volumes of data filling our computers, networks, and lives. Government agencies, scientific institutions, and businesses have all dedicated enormous resources to collecting and storing data. In reality, only a small amount of these data will ever be used because, in many cases, the volumes are simply too large to manage, or the data structures themselves are too complicated to be analyzed effectively. How could this happen? The primary reason is that the original effort to create a data set is often focused on issues such as storage efficiency; it does not include a plan for how the data will eventually be used and analyzed.
The need to understand large, complex, information-rich data sets is common to virtually all fields of business, science, and engineering. In the business world, corporate and customer data are becoming recognized as a strategic asset. The ability to extract useful knowledge hidden in these data and to act on that knowledge is becoming increasingly important in today’s competitive world. The entire process of applying a computer-based methodology, including new techniques, for discovering knowledge from data is called data mining.
Data mining is an iterative process within which progress is defined by discovery, through either automatic or manual methods. Data mining is most useful in an exploratory analysis scenario in which there are no predetermined notions about what will constitute an “interesting” outcome. Data mining is the search for new, valuable, and nontrivial information in large volumes of data. It is a cooperative effort of humans and computers. Best results are achieved by balancing the knowledge of human experts in describing problems and goals with the search capabilities of computers.
In practice, the two primary goals of data mining tend to be
prediction
and
description
.
Prediction
involves using some variables or fields in the data set to predict unknown or future values of other variables of interest.
Description
, on the other hand, focuses on finding patterns describing the data that can be interpreted by humans. Therefore, it is possible to put data-mining activities into one of two categories:
1.
predictive data mining, which
produces the model
of the system described by the given data set, or
2.
descriptive data mining, which
produces new, nontrivial information
based on the available data set.
On the predictive end of the spectrum, the goal of data mining is to produce a model, expressed as an executable code, which can be used to perform classification, prediction, estimation, or other similar tasks. On the descriptive end of the spectrum, the goal is to gain an understanding of the analyzed system by uncovering patterns and relationships in large data sets. The relative importance of prediction and description for particular data-mining applications can vary considerably. The goals of prediction and description are achieved by using data-mining techniques, explained later in this book, for the following
primary data-mining tasks
:
1.
Classification.
Discovery of a predictive learning function that classifies a data item into one of several predefined classes.
2.
Regression.
Discovery of a predictive learning function that maps a data item to a real-value prediction variable.
3.
Clustering.
A common descriptive task in which one seeks to identify a finite set of categories or clusters to describe the data.
4.
Summarization.
An additional descriptive task that involves methods for finding a compact description for a set (or subset) of data.
5.
Dependency Modeling.
Finding a local model that describes significant dependencies between variables or between the values of a feature in a data set or in a part of a data set.
6.
Change and Deviation Detection.
Discovering the most significant changes in the data set.
The more formal approach, with graphical interpretation of data-mining tasks for complex and large data sets and illustrative examples, is given in Chapter 4. Current introductory classifications and definitions are given here only to give the reader a feeling of the wide spectrum of problems and tasks that may be solved using data-mining technology.
The success of a data-mining engagement depends largely on the amount of energy, knowledge, and creativity that the designer puts into it. In essence, data mining is like solving a puzzle. The individual pieces of the puzzle are not complex structures in and of themselves. Taken as a collective whole, however, they can constitute very elaborate systems. As you try to unravel these systems, you will probably get frustrated, start forcing parts together, and generally become annoyed at the entire process, but once you know how to work with the pieces, you realize that it was not really that hard in the first place. The same analogy can be applied to data mining. In the beginning, the designers of the data-mining process probably did not know much about the data sources; if they did, they would most likely not be interested in performing data mining. Individually, the data seem simple, complete, and explainable. But collectively, they take on a whole new appearance that is intimidating and difficult to comprehend, like the puzzle. Therefore, being an analyst and designer in a data-mining process requires, besides thorough professional knowledge, creative thinking and a willingness to see problems in a different light.
Data mining is one of the fastest growing fields in the computer industry. Once a small interest area within computer science and statistics, it has quickly expanded into a field of its own. One of the greatest strengths of data mining is reflected in its wide range of methodologies and techniques that can be applied to a host of problem sets. Since data mining is a natural activity to be performed on large data sets, one of the largest target markets is the entire data-warehousing, data-mart, and decision-support community, encompassing professionals from such industries as retail, manufacturing, telecommunications, health care, insurance, and transportation. In the business community, data mining can be used to discover new purchasing trends, plan investment strategies, and detect unauthorized expenditures in the accounting system. It can improve marketing campaigns and the outcomes can be used to provide customers with more focused support and attention. Data-mining techniques can be applied to problems of business process reengineering, in which the goal is to understand interactions and relationships among business practices and organizations.
Many law enforcement and special investigative units, whose mission is to identify fraudulent activities and discover crime trends, have also used data mining successfully. For example, these methodologies can aid analysts in the identification of critical behavior patterns, in the communication interactions of narcotics organizations, the monetary transactions of money laundering and insider trading operations, the movements of serial killers, and the targeting of smugglers at border crossings. Data-mining techniques have also been employed by people in the intelligence community who maintain many large data sources as a part of the activities relating to matters of national security. Appendix B of the book gives a brief overview of the typical commercial applications of data-mining technology today. Despite a considerable level of overhype and strategic misuse, data mining has not only persevered but matured and adapted for practical use in the business world.
1.2 DATA-MINING ROOTS
Looking at how different authors describe data mining, it is clear that we are far from a universal agreement on the definition of data mining or even what constitutes data mining. Is data mining a form of statistics enriched with learning theory or is it a revolutionary new concept? In our view, most data-mining problems and corresponding solutions have roots in classical data analysis. Data mining has its origins in various disciplines, of which the two most important are
statistics
and
machine learning
. Statistics has its roots in mathematics; therefore, there has been an emphasis on mathematical rigor, a desire to establish that something is sensible on theoretical grounds before testing it in practice. In contrast, the machine-learning community has its origins very much in computer practice. This has led to a practical orientation, a willingness to test something out to see how well it performs, without waiting for a formal proof of effectiveness.
If the place given to mathematics and formalizations is one of the major differences between statistical and machine-learning approaches to data mining, another is the relative emphasis they give to models and algorithms. Modern statistics is almost entirely driven by the notion of a model. This is a postulated structure, or an approximation to a structure, which could have led to the data. In place of the statistical emphasis on models, machine learning tends to emphasize algorithms. This is hardly surprising; the very word “learning” contains the notion of a process, an implicit algorithm.
Basic modeling principles in data mining also have roots in
control theory,
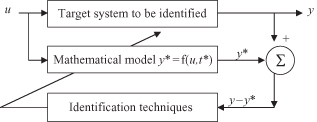
which is primarily applied to engineering systems and industrial processes. The problem of determining a mathematical model for an unknown system (also referred to as the target system) by observing its input–output data pairs is generally referred to as system identification. The purposes of system identification are multiple and, from the standpoint of data mining, the most important are to predict a system’s behavior and to explain the interaction and relationships between the variables of a system.
System identification generally involves two top-down steps:
1.
Structure Identification.
In this step, we need to apply a priori knowledge about the target system to determine a class of models within which the search for the most suitable model is to be conducted. Usually this class of models is denoted by a parameterized function
y
= f(
u,t
), where y is the model’s output,
u
is an input vector, and
t
is a parameter vector. The determination of the function f is problem-dependent, and the function is based on the designer’s experience, intuition, and the laws of nature governing the target system.
2.
Parameter Identification.
In the second step, when the structure of the model is known, all we need to do is apply optimization techniques to determine parameter vector
t
such that the resulting model
y
* = f(
u,t
*) can describe the system appropriately.
In general, system identification is not a one-pass process: Both structure and parameter identification need to be done repeatedly until a satisfactory model is found. This iterative process is represented graphically in Figure
1.1
. Typical steps in every iteration are as follows:
1.
Specify and parameterize a class of formalized (mathematical) models,
y
* = f(
u,t*
), representing the system to be identified.
2.
Perform parameter identification to choose the parameters that best fit the available data set (the difference
y
−
y
* is minimal).
3.
Conduct validation tests to see if the model identified responds correctly to an unseen data set (often referred to as test, validating or checking data set).
4.
Terminate the process once the results of the validation test are satisfactory.
Figure 1.1.
Block diagram for parameter identification.