Data Mining (6 page)
Authors: Mehmed Kantardzic
The model of a data-mining process should help to plan, work through, and reduce the cost of any given project by detailing procedures to be performed in each of the phases. The model of the process should provide a complete description of all phases from problem specification to deployment of the results. Initially the team has to answer the key question: What is the ultimate purpose of mining these data, and more specifically, what are the business goals? The key to success in data mining is coming up with a precise formulation of the problem the team is trying to solve. A focused statement usually results in the best payoff. The knowledge of an organization’s needs or scientific research objectives will guide the team in formulating the goal of a data-mining process. The prerequisite to knowledge discovery is understanding the data and the business. Without this deep understanding, no algorithm, regardless of sophistication, is going to provide results in which a final user should have confidence. Without this background a data miner will not be able to identify the problems he/she is trying to solve, or to even correctly interpret the results. To make the best use of data mining, we must make a clear statement of project objectives. An effective statement of the problem will include a way of measuring the results of a knowledge discovery project. It may also include details about a cost justification. Preparatory steps in a data-mining process may also include analysis and specification of a type of data mining task, and selection of an appropriate methodology and corresponding algorithms and tools. When selecting a data-mining product, we have to be aware that they generally have different implementations of a particular algorithm even when they identify it with the same name. Implementation differences can affect operational characteristics such as memory usage and data storage, as well as performance characteristics such as speed and accuracy.
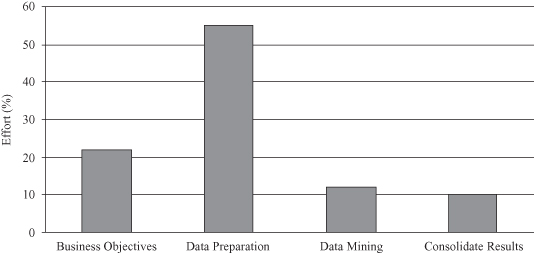
The data-understanding phase starts early in the project, and it includes important and time-consuming activities that could make enormous influence on the final success of the project. “Get familiar with the data” is the phrase that requires serious analysis of data, including source of data, owner, organization responsible for maintaining the data, cost (if purchased), storage organization, size in records and attributes, size in bytes, security requirements, restrictions on use, and privacy requirements. Also, the data miner should identify data-quality problems and discover first insights into the data, such as data types, definitions of attributes, units of measure, list or range of values, collection information, time and space characteristics, and missing and invalid data. Finally, we should detect interesting subsets of data in these preliminary analyses to form hypotheses for hidden information. The important characteristic of a data-mining process is the relative time spent to complete each of the steps in the process, and the data are counterintuitive as presented in Figure
1.6
. Some authors estimate that about 20% of the effort is spent on business objective determination, about 60% on data preparation and understanding, and only about 10% for data mining and analysis.
Figure 1.6.
Effort in data-mining process.
Technical literature reports only on successful data-mining applications. To increase our understanding of data-mining techniques and their limitations, it is crucial to analyze not only successful but also unsuccessful applications. Failures or dead ends also provide valuable input for data-mining research and applications. We have to underscore the intensive conflicts that have arisen between practitioners of “digital discovery” and classical, experience-driven human analysts objecting to these intrusions into their hallowed turf. One good case study is that of U.S. economist Orley Ashenfelter, who used data-mining techniques to analyze the quality of French Bordeaux wines. Specifically, he sought to relate auction prices to certain local annual weather conditions, in particular, rainfall and summer temperatures. His finding was that hot and dry years produced the wines most valued by buyers. Ashenfelter’s work and analytical methodology resulted in a deluge of hostile invective from established wine-tasting experts and writers. There was a fear of losing a lucrative monopoly, and the reality that a better informed market is more difficult to manipulate on pricing. Another interesting study is that of U.S. baseball analyst William James, who applied analytical methods to predict which of the players would be most successful in the game, challenging the traditional approach. James’s statistically driven approach to correlating early performance to mature performance in players resulted very quickly in a barrage of criticism and rejection of the approach.
There have been numerous claims that data-mining techniques have been used successfully in counter-terrorism intelligence analyses, but little has surfaced to support these claims. The idea is that by analyzing the characteristics and profiles of known terrorists, it should be feasible to predict who in a sample population might also be a terrorist. This is actually a good example of potential pitfalls in the application of such analytical techniques to practical problems, as this type of profiling generates hypotheses, for which there may be good substantiation. The risk is that overly zealous law enforcement personnel, again highly motivated for good reasons, overreact when an individual, despite his or her profile, is not a terrorist. There is enough evidence in the media, albeit sensationalized, to suggest this is a real risk. Only careful investigation can prove whether the possibility is a probability. The degree to which a data-mining process supports business goals or scientific objectives of data explorations is much more important than the algorithms and data-mining tools it uses.
1.7 ORGANIZATION OF THIS BOOK
After introducing the basic concepts of data mining in Chapter 1, the rest of the book follows the basic phases of a data-mining process. In Chapters 2 and 3 the common characteristics of raw, large, data sets and the typical techniques of data preprocessing are explained. The text emphasizes the importance and influence of these initial phases on the final success and quality of data-mining results. Chapter 2 provides basic techniques for transforming raw data, including data sets with missing values and with time-dependent attributes. Outlier analysis is a set of important techniques for preprocessing of messy data and is also explained in this chapter. Chapter 3 deals with reduction of large data sets and introduces efficient methods for reduction of features, values, and cases. When the data set is preprocessed and prepared for mining, a wide spectrum of data-mining techniques is available, and the selection of a technique or techniques depends on the type of application and data characteristics. In Chapter 4, before introducing particular data-mining methods, we present the general theoretical background and formalizations applicable for all mining techniques. The essentials of the theory can be summarized with the question: How can one learn from data? The emphasis in Chapter 4 is on statistical learning theory and the different types of learning methods and learning tasks that may be derived from the theory. Also, problems of evaluation and deployment of developed models is discussed in this chapter.
Chapters 5 to 11 give an overview of common classes of data-mining techniques. Predictive methods are described in Chapters 5 to 8, while descriptive data mining is given in Chapters 9 to 11. Selected statistical inference methods are presented in Chapter 5, including Bayesian classifier, predictive and logistic regression, analysis of variance (ANOVA), and log-linear models. Chapter 6 summarizes the basic characteristics of the C4.5 algorithm as a representative of logic-based techniques for classification problems. Basic characteristics of the Classification and Regression Trees (CART) approach are also introduced and compared with C4.5 methodology. Chapter 7 discusses the basic components of artificial neural networks and introduces two classes: multilayer perceptrons and competitive networks as illustrative representatives of a neural-network technology. Practical applications of a data-mining technology show that the use of several models in predictive data mining increases the quality of results. This approach is called ensemble learning, and basic principles are given in Chapter 8.
Chapter 9 explains the complexity of clustering problems and introduces agglomerative, partitional, and incremental clustering techniques. Different aspects of local modeling in large data sets are addressed in Chapter 10, and common techniques of association-rule mining are presented. Web mining and text mining are becoming one of the central topics for many researchers, and results of these activities are new algorithms summarized in Chapter 11. There are a number of new topics and recent trends in data mining that are emphasized in the last 7 years. Some of these topics, such as graph mining, and temporal, spatial, and distributed data mining, are covered in Chapter 12. Important legal restrictions and guidelines, and security and privacy aspects of data mining applications are also introduced in this chapter. Most of the techniques explained in Chapters 13 and 14, about genetic algorithms and fuzzy systems, are not directly applicable in mining large data sets. Recent advances in the field show that these technologies, derived from soft computing, are becoming more important in better representing and computing data as they are combined with other techniques. Finally, Chapter 15 recognizes the importance of data-mining visualization techniques, especially those for representation of large-dimensional samples.
It is our hope that we have succeeded in producing an informative and readable text supplemented with relevant examples and illustrations. All chapters in the book have a set of review problems and reading lists. The author is preparing a solutions manual for instructors who might use the book for undergraduate or graduate classes. For an in-depth understanding of the various topics covered in this book, we recommend to the reader a fairly comprehensive list of references, given at the end of each chapter. Although most of these references are from various journals, magazines, and conference and workshop proceedings, it is obvious that, as data mining is becoming a more mature field, there are many more books available, covering different aspects of data mining and knowledge discovery. Finally, the book has two appendices with useful background information for practical applications of data-mining technology. In Appendix A we provide an overview of the most influential journals, conferences, forums, and blogs, as well as a list of commercially and publicly available data-mining tools, while Appendix B presents a number of commercially successful data-mining applications.
The reader should have some knowledge of the basic concepts and terminology associated with data structures and databases. In addition, some background in elementary statistics and machine learning may also be useful, but it is not necessarily required as the concepts and techniques discussed within the book can be utilized without deeper knowledge of the underlying theory.
1.8 REVIEW QUESTIONS AND PROBLEMS
1.
Explain why it is not possible to analyze some large data sets using classical modeling techniques.
2.
Do you recognize in your business or academic environment some problems in which the solution can be obtained through classification, regression, or deviation? Give examples and explain.
3.
Explain the differences between statistical and machine-learning approaches to the analysis of large data sets.
4.
Why are preprocessing and dimensionality reduction important phases in successful data-mining applications?
5.
Give examples of data where the time component may be recognized explicitly, and other data where the time component is given implicitly in a data organization.
6.
Why is it important that the data miner understand data well?
7.
Give examples of structured, semi-structured, and unstructured data from everyday situations.
8.
Can a set with 50,000 samples be called a large data set? Explain your answer.
9.
Enumerate the tasks that a data warehouse may solve as a part of the data-mining process.
10.
Many authors include OLAP tools as a standard data-mining tool. Give the arguments for and against this classification.
11.
Churn is a concept originating in the telephone industry. How can the same concept apply to banking or to human resources?
12.
Describe the concept of actionable information.
13.
Go to the Internet and find a data-mining application. Report the decision problem involved, the type of input available, and the value contributed to the organization that used it.
14.
Determine whether or not each of the following activities is a data-mining task. Discuss your answer.
(a)
Dividing the customers of a company according to their age and sex.
(b)
Classifying the customers of a company according to the level of their debt.
(c)
Analyzing the total sales of a company in the next month based on current-month sales.
(d)
Classifying a student database based on a department and sorting based on student identification numbers.
(e)
Determining the influence of the number of new University of Louisville students on the stock market value.
(f)
Estimating the future stock price of a company using historical records.
(g)
Monitoring the heart rate of a patient with abnormalities.
(h)
Monitoring seismic waves for earthquake activities.
(i)
Extracting frequencies of a sound wave.
(j)
Predicting the outcome of tossing a pair of dice.