Data Mining (92 page)
Authors: Mehmed Kantardzic

If we carry this same procedure out to 100 iterations, we achieve the following results:



Additional iterations produce the same results. From this we can see a stable ordering emerge. B has the largest PageRank value having two in-links, more than any other. However, page A is not far behind, since page B has only a single link to page A without dividing its PageRank value among a number of outbound links.
Next we consider the example used for the HITS algorithm, which is applied on the graph in Figure
11.5
a. The PageRank of this graph with a dampening factor of 0.85 is given in Figure
11.5
b after running 100 iterations. A reader may, for practice, check the results after the first iteration, or implement the PageRank algorithm and check final results in Figure
11.5
b.
Figure 11.5.
An example graph and scoring for PageRank also used with HITS. (a) Subgraph of linked pages; (b) calculated PageRank for given graph.
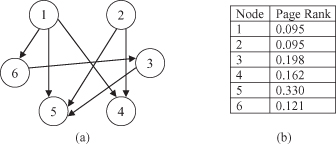
From the values given in Figure
11.5
b we can see that node 5 has the highest PageRank by far and also has the highest in-degree or edges pointing in to it. Surprising perhaps is that node 3 has the next highest score, having a score higher than node 4, which has more in-edges. The reason is that node 6 has only one out-edge pointing to node 3, while the edges pointing to node 4 are each one of multiple out-edges. Lastly, as expected, the lowest ranked edges are those with no in-edges, nodes 1 and 2.
One of the main contributions of Google’s founders is implementation and experimental evaluation of the PageRank algorithm. They included a database of web sites with 161 million links, and the algorithm converge in 45 iterations. Repeated experiments with 322 million links converged in 52 iterations. These experiments were evidence that PageRank converges in
log(n)
time where
n
is number of links, and it is applicable for a growing Web. Of course, the initial version of the PageRank algorithm, explained in a simplified form in this text, had numerous modifications to evolve into the current commercial version implemented in the Google search engine.
11.6 TEXT MINING
Enormous amounts of knowledge reside today in text documents that are stored either within organizations or are freely available. Text databases are rapidly growing because of the increasing amounts of information available in electronic form, such as electronic publications, digital libraries, e-mail, and the World Wide Web. Data stored in most text databases are semi-structured, and special data-mining techniques, called text mining, have been developed for discovering new information from large collections of textual data.
In general, there are two key technologies that make online text mining possible. One is
Internet search
capabilities and the other is the
text analysis
methodology.
Internet search
has been around for a few years. With the explosion of Web sites in the past decade, numerous search engines designed to help users find content appeared practically overnight. Yahoo, Alta Vista, and Excite are three of the earliest, while Google and Bing are the most popular in recent years. Search engines operate by indexing the content in a particular Web site and allowing users to search these indices. With the new generation of Internet-search tools, users can gain relevant information by processing a smaller amount of links, pages, and indices.
Text analysis
, as a field, has been around longer than Internet search. It has been a part of the efforts to make computers understand natural languages, and it is commonly thought of as a problem for artificial intelligence. Text analysis can be used anywhere where there is a large amount of text that needs to be analyzed. Although automatic processing of documents using different techniques does not allow the depth of analysis that a human can bring to the task, it can be used to extract key points in the text, categorize documents, and generate summaries in a situation when a large number of documents makes manual analysis impossible.
To understand the details of text documents you can either search for keywords, or you can try to categorize the semantic content of the document itself. When identifying keywords in text documents, you are looking at defining specific details or elements within documents that can be used to show connections or relationships with other documents. In the IR domain, documents have been traditionally represented in the vector space model. Documents are tokenized using simple syntactic rules (such as white-space delimiters in English), and tokens are transformed to canonical form (e.g., “reading” to “read,” “is,” “was,” and “are” to “be”). Each canonical token represents an axis in a Euclidean space. Documents are vectors in this n-dimensional space. If a token
t
called term occurs
n
times in document
d
, then the
t
th coordinate of
d
is simply
n.
One may choose to normalize the length of the document to 1, using the L
1
, L
2
, or L
∞
norms:
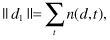 |  | 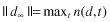 |
where n(
d
,
t
) is the number of occurrences of a term t in a document d. These representations do not capture the fact that some terms, also called keywords (like “algorithm”), are more important than others (like “the” and “is”) in determining document content. If t occurs in n
t
out of N documents, n
t
/N gives a sense of rarity, and hence, the importance of the term. The inverse document frequency, IDF = 1 + log (n
t
/N), is used to stretch the axes of the vector space differentially. Thus the
t
th coordinate of document d may be represented with the value (n(d,t)/||d
1
||) × IDF(t) in the weighted vector space model. In spite of being extremely crude and not capturing any aspect of language or semantics, this model often performs well for its intended purpose. Also, in spite of minor variations, all these models of text regard documents as multisets of terms, without paying attention to ordering between terms. Therefore, they are collectively called bag-of-words models. Very often, the outputs from these keyword approaches can be expressed as relational data sets that may then be analyzed using one of the standard data-mining techniques.