Data Mining (37 page)
Authors: Mehmed Kantardzic
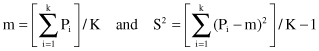
We have a statistic that is t distributed with K-1 degrees of freedom, and the following test:
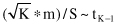
Thus, the K-fold cross-validation paired
t
-test rejects the hypothesis that two algorithms have the same error rate at significance level α, if previous value is outside interval (−t
α/2,K-1
, t
α/2,K-1
). For example, the threshold values could be for α = 0.05 and K = 10 or 30: t
0.025, 9
= 2.26, and t
0.025, 29
= 2.05.
Over time, all systems evolve. Thus, from time to time the model will have to be retested, retrained, and possibly completely rebuilt. Charts of the residual differences between forecasted and observed values are an excellent way to monitor model results.
4.9 90% ACCURACY: NOW WHAT?
Often forgotten in texts on data mining is a discussion of the deployment process. Any data-mining student may produce a model with relatively high accuracy over some small data set using the tools available. However, an experienced data miner sees beyond the creation of a model during the planning stages. There needs to be a plan created to evaluate how useful a data-mining model is to a business, and how the model will be rolled out. In a business setting the value of a data-mining model is not simply the accuracy, but how that model can impact the bottom line of a company. For example, in fraud detection, algorithm A may achieve an accuracy of 90% while algorithm B achieves 85% on training data. However, an evaluation of the business impact of each may reveal that algorithm A would likely underperform algorithm B because of larger number of very expensive false negative cases. Additional financial evaluation may recommend algorithm B for the final deployment because with this solutions company saves more money. A careful analysis of the business impacts of data-mining decisions gives much greater insight of a data-mining model.
In this section two case studies are summarized. The first case study details the deployment of a data-mining model that improved the efficiency of employees in finding fraudulent claims at an insurance company in Chile. The second case study involves a system deployed in hospitals to aid in counting compliance with industry standards in caring for individuals with cardiovascular disease (CVD).
4.9.1 Insurance Fraud Detection
In 2005, the insurance company Banmedica S.A. of Chile received 800 digital medical claims per day. The process of identifying fraud was entirely manual. Those responsible for identifying fraud had to look one-by-one at medical claims to find fraudulent cases. Instead it was hoped that data-mining techniques would aid in a more efficient discovery of fraudulent claims.
The first step in the data-mining process required that the data-mining experts gain a better understanding of the processing of medical claims. After several meetings with medical experts, the data-mining experts were able to better understand the business process as it related to fraud detection. They were able to determine the current criteria used in manually discriminating between claims that were approved, rejected, and modified. A number of known fraud cases were discussed and the behavioral patterns that revealed these documented fraud cases.
Next, two data sets were supplied. The first data set contained 169 documented cases of fraud. Each fraudulent case took place over an extended period of time, showing that time was an important factor in these decisions as cases developed. The second data set contained 500,000 medical claims with labels supplied by the business of “approved,” “rejected,” or “reduced.”
Both data sets were analyzed in detail. The smaller data set of known fraud cases revealed that these fraudulent cases all involved a small number of medical professionals, affiliates, and employers. From the original paper, “19 employers and 6 doctors were implicated with 152 medical claims.” The labels of the larger data set were revealed to be not sufficiently accurate for data mining. Contradictory data points were found. A lack of standards in recording these medical claims, with a large number of missing values contributed to the poorly labeled data set. Instead of the larger 500,000 point data set, the authors were “forced” to rebuild a subset of thesee data. This required manual labeling of the subset.
The manual labeling would require a much smaller set of data points to be used from the original 500,000. To cope with a smaller set of data points, the problem was split into four smaller problems, namely identifying fraudulent medical claims, affiliates, medical professionals, and employers. Individual data sets were constructed for each of these four subtasks ranging in size from 2838 samples in the medical claims task to 394 samples in the employer subtask. For each subtask a manual selection of features was performed. This involved selecting only one feature from highly correlated features, replacing categorical features with numerical features, and design new features that “summarize temporal behavior over an extended time span.” The original 125 features were paired down to between 12 and 25 features depending on the subtask. Additionally, the output of all other subtasks became inputs to each subtask, thus providing feedback to each subtask. Last, 2% of outliers were removed and features were normalized.
When modeling the data it was found that initially the accuracy of a single neural network on these data sets could vary by as much as 8.4%. Instead of a single neural network for a particular data set, a committee of neural networks was used. Each data set was also divided into a training set, a validation set, and a testing set to avoid overfitting the data. At this point it was also decided that each of the four models would be retrained monthly to keep up with the ever evolving process of fraud.
Neural networks and committees of neural networks output scores rather than an absolute fraud classification. It was necessary that a threshold be set for the output. The threshold was decided after accounting for personnel costs, false alarm costs, and the cost of not detecting a particular instance of fraud. All of these factors figured into an ROC curve to decide upon acceptable false and true positive rates. When the medical claims model using the input of the other three subtasks scored a medical claim above the chosen threshold, then a classification of fraud is given to that claim. The system was tested on a historical data set of 8819 employers that contains 418 instances of fraud. After this historical data set was split into training, validation, and test set, the results showed that the system identified 73.4% of the true fraudsters and had a false positive rate of 6.9%.
The completed system was then run each night giving each new medical claim a fraud probability. The claims are then reviewed being sorted by the given probabilities. There were previously very few documented cases of fraud. After implementation there were approximately 75 rejected claims per month. These newly found cases of fraud accounted for nearly 10% of the raw overall costs to the company. Additionally, the culture of fraud detection changed. A taxonomy of the types of fraud was created and further improvements were made on the manual revision process. The savings covered the operational costs and increased the quality of health coverage.
Overall this project was a big success. The authors spent a lot of time first understanding the problem and second analyzing the data in detail, before the data was modeled. The final models produced were analyzed in terms of real business costs. In the end the results showed that the costs of the project were justified and Banmedica S.A. greatly benefited from the final system.
4.9.2 Improving Cardiac Care
CVD leads to nearly 1 million deaths (or 38% of all deaths) in the United States per year. Additionally, in 2005 the estimated cost of CVD was $394 billion compared with an estimated $190 billion on all cancers combined. CVD is a real problem that appears to be growing in the number of lives claimed and the percent of the population that will be directly affected by this disease. Certainly we can gain a better understanding of this disease. There already exist guidelines for the care of patients with CVD that were created by panels of experts. With the current load on the medical system, doctors are able to only spend a short amount of time with each patient. With the large number of guidelines that exists, it is not reasonable to expect that doctors will follow every guideline on every patient. Ideally a system would aid a doctor in following the given guidelines without adding additional overheads.
This case study outlines the use and deployment of a system called REMIND, which is meant both to find patients at need within the system, and to enable a better tracking of when patients are being cared for according to guidelines. Currently two main types of records are kept for each patient, financial and clinical. The financial records are used for billing. These records use standardized codes (e.g., ICD-9) for doctor assessments and drugs prescribed. This standardization makes it straightforward for computer systems to extract information from these records and used by data-mining processes. However, it has been found that these codes are accurate only 60–80% of the time for various reasons. One reason is that when these codes are used for billing, although two conditions are nearly identical in symptoms and prescriptions, the amount of money that will be paid out by an insurer may be very different. The other form of records kept is clinical records. Clinical records are made up of unstructured text, and allow for the transfer of knowledge about a patient’s condition and treatments from one doctor to another. These records are much more accurate, but are not in a form that is easily used by automated computer systems.
It is not possible that with great demands on the time of doctors and nurses that additional data may be recorded specifically for this system. Instead, the REMIND system combines data from all available systems. This includes extracting knowledge from the unstructured clinical records. The REMIND system combines all available sources of data present, then using redundancy in data the most likely state of the patient is found. For example to determine a patient is diabetic one may use any of the following pieces of data: billing code 250.xx for diabetes, a free text dictation identifying a diabetic diagnosis, a blood sugar value >300, a treatment of insulin or oral antidiabetic, or a common diabetic complication. The likelihood of the patient having diabetes increases as more relevant information is found. The REMIND system uses extracted information from all possible data sources, combined in a Bayesian network. The various outputs of the network are used along with temporal information to find the most probable sequence of states with a predefined disease progression modeled as a Markov model. The probabilities and structure of the Bayesian network are provided as domain knowledge provided beforehand by experts and tunable per deployment. The domain knowledge in the REMIND system is fairly simple as stated by the author of the system. Additionally, by using a large amount of redundancy the system performs well for a variety of probability settings and temporal settings for the disease progression. However, before a wide distribution of the REMIND system a careful tuning of all the parameters must take place.
One example deployment was to the South Carolina Heart Center where the goal was to identify among 61,027 patients those at risk of Sudden Cardiac Death (SCD). Patients who have previously suffered a myocardial infarction (MI; heart attack) are at the highest risk of SCD. In 1997 a study was performed on the efficacy of implantable cardioverter defribillators (ICDs). It was found that patients, with a prior MI and low ventricular function, had their 20-month mortality rate drop from 19.8% to 14.2%. This implantation is now a standard recommendation. Previous to the REMIND system one had two options to find who would require the implantation of an ICD. The first option is to manually review the records of all patients to identify those who were eligible for an ICD. This would be extremely time-consuming considering the large number of records. The other approach would be to evaluate the need for an ICD during regular checkups. However, not all patients come in for regular checkups and there would be a high chance that not every patient would be carefully considered for the need of an ICD. The REMIND system was given access to billing and demographics databases and transcribed free text including histories, physical reports, physician progress notes, and lab reports. From these data the REMIND system processed all records on a single laptop in 5 h and found 383 patients who qualified for an ICD.