Data Mining (70 page)
Authors: Mehmed Kantardzic
Boosting
is the most widely used ensemble method and one of the most powerful learning ideas introduced in the ensemble-learning community. Originally designed for classification, it can also be extended to regression. The algorithm first creates a “weak” classifier, that is, it suffices that its accuracy on the training set is slightly better than random guessing. Samples are given initial weights, and usually it starts with uniform weighting. For the following iterations, the samples are reweighted to focus the system on samples that are not correctly classified with a recently learned classifier. During each step of learning: (1) increase weights of the samples that are not correctly learned by the weak learner, and (2) decrease weights of the samples that are correctly learned by the weak learner. Final classification is based on a weighted vote of weak classifiers generated in iterations.
8.4 ADABOOST
The original boosting algorithm combined three weak learners to generate a strong, high quality learner.
AdaBoost
, short for “adaptive boosting,” is the most popular boosting algorithm. AdaBoost combine “weak” learners into a highly accurate classifier to solve difficult highly nonlinear problems. Instead of sampling, as in a bagging approach, AdaBoost reweighs samples. It uses the same training set over and over again (thus it need not be large) and it may keep adding weak learners until a target training error is reached.
Given a training data set: {(x1, y1), … , (xm, ym)} where xi ∈ X and yi ∈ {−1, +1}, when a weak classifier is trained with the data, for each input sample x
i
the classifier will give classification h(x
i
) (where h(x
i
) ∈ {−1, +1}). With these assumptions the main steps of the AdaBoost algorithm are presented in Figure
8.8
.
Simplicity and easy implementation are the main reasons why AdaBoost is very popular. It can be combined with any classifiers including neural networks, decision trees, or nearest neighbor classifiers. The algorithm requires almost no parameters to tune, and is still very effective even for the most complex classification problems, but at the same time it could be sensitive to noise and outliers.
Ensemble-learning approach showed all advantages in one very famous application, Netflix $1 million competition. The Netflix prize required substantial improvement in the accuracy of predictions on how much someone is going to love a movie based on his or her previous movie preferences. Users’ rating for movies was 1 to 5 stars; therefore, the problem was classification task with five classes. Most of the top-ranked competitors have used some variations of ensemble learning, showing its advantages in practice. Top competitor
BellKor
team explains ideas behind its success: “Our final solution consists of blending 107 individual predictors. Predictive accuracy is substantially improved when blending multiple predictors. Our experience is that most efforts should be concentrated in deriving substantially different approaches, rather than refining a single technique. Consequently, our solution is an ensemble of many methods.”
8.5 REVIEW QUESTIONS AND PROBLEMS
1.
Explain the basic idea of ensemble learning, and discuss why the ensemble mechanism is able to improve prediction accuracy of a model.
2.
Designing an ensemble model, there are factors that directly affect the accuracy of the ensemble. Explain those factors and approaches to each of them.
3.
Bagging and boosting are very famous ensemble approaches. Both of them generate a single predictive model from each different training set. Discuss the differences between bagging and boosting, and explain the advantages and disadvantages of each of them.
4.
Propose the efficient boosting approach for a large data set.
5.
In the bagging methodology, a subset is formed by samples that are randomly selected with replacement from training samples. On average, a subset contains approximately what percentage of training samples?
6.
In Figure
8.7
, draw a picture of the next distribution
D
4
.
Figure 8.7.
AdaBoost iterations.

7.
In equation (2) of the AdaBoost algorithm (Fig.
8.8
),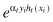 replaces the term of
replaces the term of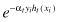 . Explain how and why this change influences the AdaBoost algorithm.
. Explain how and why this change influences the AdaBoost algorithm.
Figure 8.8.
AdaBoost algorithm.

Figure 8.9.
Top competitors in 2007/2008 for Netflix award.

8.
Consider the following data set, where there are 10 samples with one dimension and two classes:
Training samples:

(a)
Determine ALL the best one-level binary decision trees.
(e.g., IF
f
1
≤ 0.35, THEN Class is 1, and IF
f
1
> 0.35, THEN Class is −1. The accuracy of that tree is 80%)
(b)
We have the following five training data sets randomly selected from the above training samples. Apply the bagging procedure using those training data sets.
(i)
Construct the best one-level binary decision tree from each training data set.
(ii)
Predict the training samples using each constructed one-level binary decision tree.
(iii)
Combine outputs predicted by each decision tree using voting method
(iv)
What is the accuracy rate provided by bagging?
Training Data Set 1:
Training Data Set 2:
Training Data Set 3:
Training Data Set 4: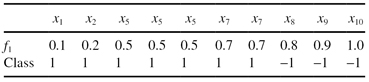
Training Data Set 5:
(c)
Applying the AdaBoost algorithm (Fig.
8.8
) to the above training samples, we generate the following initial one-level binary decision tree from those samples:


To generate the next decision tree, what is the probability (D
2
in Fig.
8.8
) that each sample is selected to the training data set? (α
t
is defined as an accuracy rate of the initial decision tree on training samples.)